
1. 基础
1.1. 基本数据类型
C、N、D、T、I、F、P、X、string、Xstring
P:默认为8字节,最大允许16字节。最大整数位:16*2 = 32 - 1 = 31 -14(允许最大小数位数) = 17位整数位
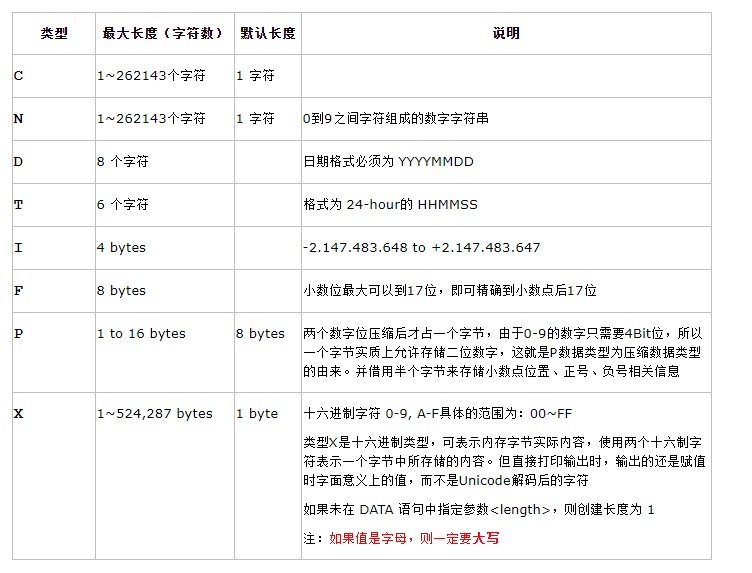
1.1.1.P类型(压缩型)数据
是一种压缩的定点数,其数据对象占据内存字节数和数值范围取定义时指定的整个数据大小和小数点后位数,如果不指定小数位,则将视为I类型。其有效数字位大小可以是从1~31位数字(小数点与正负号占用一个位置,半个字节),小数点后最多允许14个数字。
P类型的数据,可用于精确运算(这里的精确指的是存储中所存储的数据与定义时字面上所看到的大小相同,而不存在精度丢失问题——看到的就是内存中实实在在的大小)。在使用P类型时,要先选择程序属性中的选项 Fixed point arithmetic(即定点算法,一般默认选中),否则系统将P类型看用整型。其效率低于I或F类型。
"16 * 2 = 32表示了整个字面意义上允许的最大字面个数,而14表示的是字面上小数点后面允许的最大小数位,而不是指14个字节,只有这里定义时的16才表示16个字节
DATA: p(16) TYPE p DECIMALS 14 VALUE '12345678901234567.89012345678901'.
"正负符号与小数点固定要占用半个字节,一个字面上位置,并包括在这16个字节里面。
"16 * 2 = 32位包括了小数点与在正负号在内
"在定义时字面上允许最长可以达到32位,除去小数点与符号需占半个字节以后
"有效数字位可允许31位,这31位中包括了整数位与小数位,再除去定义时小
"数位为14位外,整数位最多还可达到17位,所以下面最多只能是17个9
DATA: p1(16) TYPE p DECIMALS 14 VALUE '-99999999999999999'.
"P类型是以字符串来表示一个数的,与字符串不一样的是,P类型中的每个数字位只会占用4Bit位,所以两个数字位才会占用一个字节。另外,如果定义时没有指定小数位,表示是整型,但小数点固定要占用半个字节,所以不带小数位与符号的最大与最小整数如下(最多允许31个9,而不是32个)
DATA: p1(16) TYPE p VALUE '+9999999999999999999999999999999'.
DATA: p2(16) TYPE p VALUE '-9999999999999999999999999999999'.
其实P类型是以字符串形式来表示一个小数,这样才可以作到精确,就像Java中要表示一个精确的小数要使用BigDecimal一样,否则会丢失精度。
DATA: p(9) TYPE p DECIMALS 2 VALUE '-123456789012345.12'.
WRITE: / p."123456789012345.12-
DATA: f1 TYPE f VALUE '2.0',
f2 TYPE f VALUE '1.1',
f3 TYPE f.
f3 = f1 - f2."不能精确计算
"2.0000000000000000E+00 1.1000000000000001E+00 8.9999999999999991E-01
WRITE: / f1 , f2 , f3.
DATA: p1 TYPE p DECIMALS 1 VALUE '2.0',
p2 TYPE p DECIMALS 1 VALUE '1.1',
p3 TYPE p DECIMALS 1.
p3 = p1 - p2."能精确计算
WRITE: / p1 , p2 , p3. "2.0 1.1 0.9
Java中精确计算:
publicstaticvoid main(String[] args) {
System.out.println(2.0 - 1.1);// 0.8999999999999999
System.out.println(sub(2.0, 0.1));// 1.9
}
publicstaticdouble sub(double v1, double v2) {
BigDecimal b1 = new BigDecimal(Double.toString(v1));
BigDecimal b2 = new BigDecimal(Double.toString(v2));
return b1.subtract(b2).doubleValue();
}
1.2.TYPE、LIKE
透明表(还有其它数据词典中的类型,如结构)即可看作是一种类型,也可看作是对象,所以即可使用TYPE,也可以使用LIKE:
TYPES type6 TYPE mara-matnr.
TYPES type7 LIKE mara-matnr.
DATA obj6 TYPE mara-matnr.
DATA obj7 LIKE mara-matnr.
"SFLIGHT为表类型
DATA plane LIKE sflight-planetype.
DATA plane2 TYPE sflight-planetype.
DATA plane3 LIKE sflight.
DATA plane4 TYPE sflight.
"syst为结构类型
DATA sy1 TYPE syst.
DATA sy2 LIKE syst.
DATA sy3 TYPE syst-index.
DATA sy4 LIKE syst-index.
注:定义的变量名千万别与词典中的类型相同,否则表面上即可使用TYPE也可使用LIKE,就会出现这两个关键字(Type、Like)都可用的奇怪现像,下面是定义一个变量时与词典中的结构同名的后果(导致)
DATA : BEGIN OF address2,
street(20) TYPE c,
city(20) TYPE c,
END OF address2.
DATA obj4 TYPE STANDARD TABLE OF address2."这里使用的实质上是词典中的类型address2
DATA obj5 LIKE STANDARD TABLE OF address2."这里使用是的上面定义的变量address2
上面程序编译通过,按理obj4定义是通过不过的(只能使用LIKE来引用另一定义变量的类型,TYPE是不可以的),但由于address2是数字词典中定义的结构类型,所以obj4使用的是数字词典中的结构类型,而obj5使用的是LIKE,所以使用的是address2变量的类型
1.3. DESCRIBE
DESCRIBE FIELD dobj
[TYPE typ [COMPONENTS com]]
[LENGTH ilen IN {BYTE|CHARACTER} MODE]
[DECIMALS dec]
[OUTPUT-LENGTH olen]
[HELP-ID hlp]
[EDIT MASK mask].
DESCRIBE TABLE itab [KIND knd] [LINES lin] [OCCURS n].
1.4.字符串表达式
可以使用&或&&将多个字符模板串链接起来,可以突破255个字符的限制,下面两个是等效的:
|...| & |...|
|...| && |...|
如果内容只有字面常量文本(没有变量表达式或控制字符\r \n \t),则不需要使用字符模板,可这样(如果包含了这些控制字符时,会原样输出,所以有这些控制字符时,请使用 |...|将字符包起来):
`...` && `...`
但是上面3个与下面3个是不一样的:
`...` & `...`
'...' & '...'
'...' && '...'
上面前两个还是会受255个字符长度限制,最后一个虽然不受255限制,但尾部空格会被忽略
字面常量文本(literal text)部分,使用 ||括起来,不能含有控制字符(如 \r \n \t这些控制字符),特殊字符 |{ } \需要使用 \进行转义:
txt = |Characters \|, \{, and \} have to be escaped by \\ in literal text.|.
字符串表达式:
str = |{ ( 1 + 1 ) * 2 }|."算术计算表达式
str = |{ |aa| && 'bb' }|."字符串表达式
str = |{ str }|."变量名
str = |{ strlen( str ) }|."内置函数
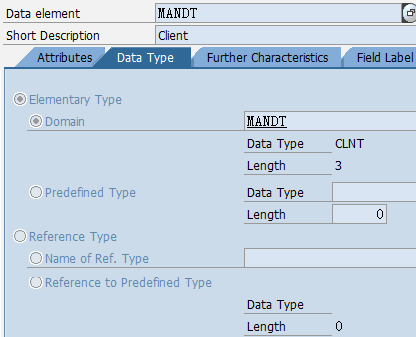
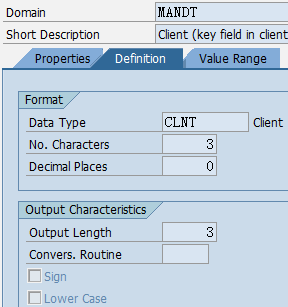
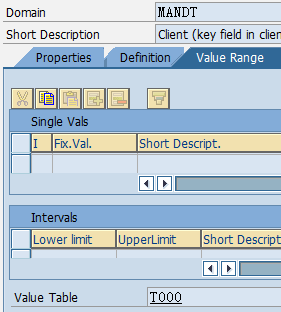
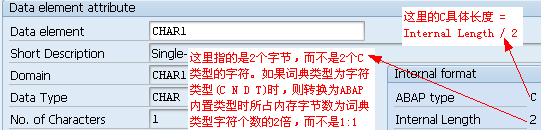
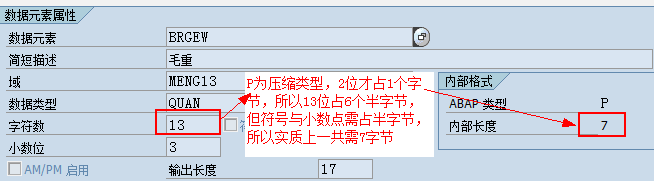
1.5. Data element、Domain
数据元素是构成结构、表的基本组件,域又定义了数据元素的技术属性。Data element主要附带Search Help、Parameter ID、以及标签描述,而类型是由Domain域来决定的。Domain主要从技术方面描述了Data element,如Data Type数据类型、Output Length输出长度、Convers. Routine转换规则、以及Value Range取值范围
将技术信息从Data element提取出来为Domain域的好处:技术信息形成的Domain可以共用,而每个表字段的业务含意不一样,会导致其描述标签、搜索帮助不一样,所以牵涉到业务部分的信息直接Data element中进行描述,而与业务无关的技术信息部分则分离出来形成Domain

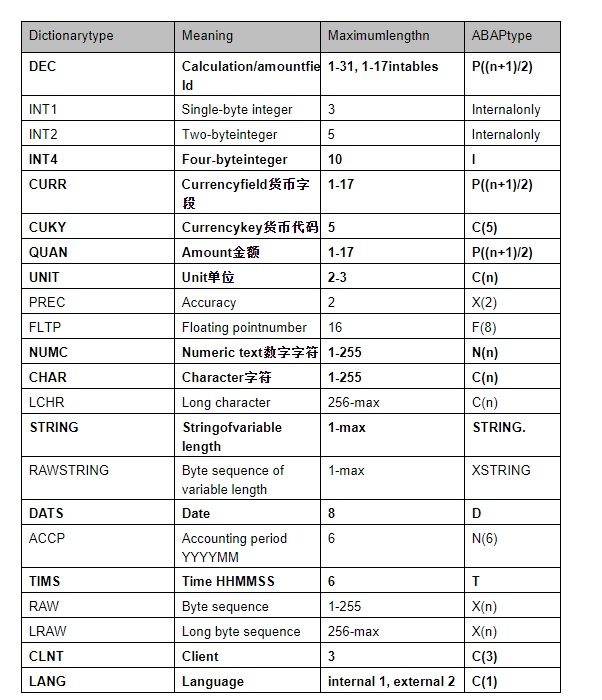
1.6. 词典预定义类型与ABAP类型映射
当你在ABAP程序中引用了ABAPDictionary,则预置Dictionary类型则会转换为相应的ABAP类型,预置的Dictionary类型转换规则表如下:
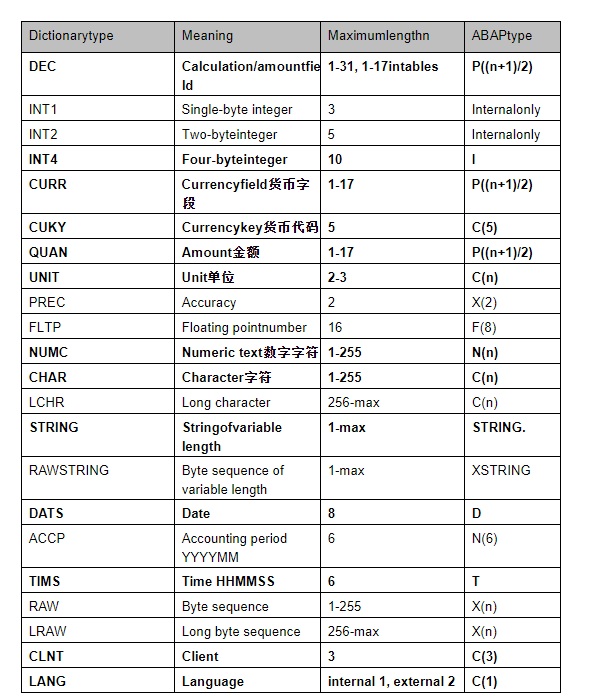
这里的“允许最大长度m”表示的是字面上允许的字符位数,而不是指底层所占内存字节数,如
int1的取值为0~255,所以是3位(不包括符号位)
int2的取值为-32768~32767,所以是5位
lLCHR and LRAW类型允许的最大值为INT2 最大值
lRAWSTRING and STRING 具有可变长度,最大值可以指定,但没有上限
lSSTRING 长度是可变的,其最大值必须指定且上限为255。与CHAR类型相比其优势是它与ABAP type string进行映射。
这些预置的Dictionary类型在创建Data element、Domain时可以引用
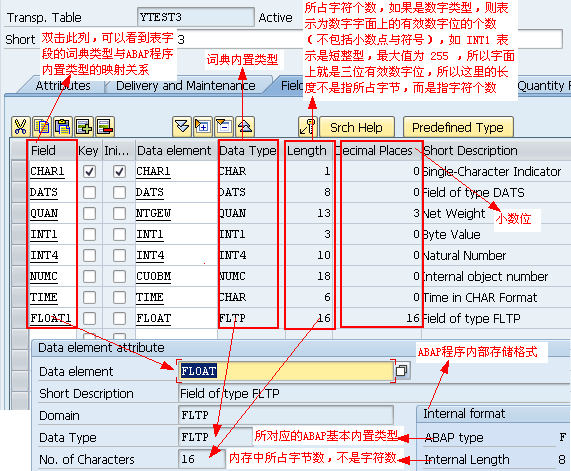
在Unicode系统中,一个字符占两个字节
1.7.字符串处理
SPLIT dobj AT sep INTO { {result1 result2 ...} | {TABLE result_tab} }必须指定足够目标字段。否则,用字段dobj的剩余部分填充最后目标字段并包含分界符;或者使用内表动态接收
SHIFT dobj {[{BY num PLACES}|{UP TO sub_string}][[LEFT|RIGHT][CIRCULAR]]}
| { {LEFT DELETING LEADING}|{RIGHT DELETING TRAILING} } pattern
对于固定长度字符串类型,shift产生的空位会使用空格或十六进制的0(如果为X类型串时)来填充
向右移动时前面会补空格,固定长度类型字符串与String结果是不一样:String类型右移后不会被截断,只是字串前面补相应数量的空格,但如果是C类型时,则会截断;左移后后面是否被空格要看是否是固定长度类型的字符串还是变长的String类型串,左移后C类型会补空格,String类型串不会(会缩短)
CIRCULAR:将移出的字符串放在左边或者左边
pattern:只要前导或尾部字符在指定的pattern字符集里就会被去掉,直到第一个不在模式pattern的字符止
CONDENSE [NO-GAPS].如果是C类型只去掉前面的空格(因为是定长,即使后面空格去掉了,左对齐时后面会补上空格),如果是String类型,则后面空格也会被去掉;字符串中间的多个连续的空格使用一个空格替换(String类型也是这样);NO-GAPS:字符串中间的所有空格都也都会去除(String类型也是这样);空格去掉后会左对齐[kənˈdens]
CONCATENATE {dobj1 dobj2 ...}|{LINES OF itab}[kənˈkatɪneɪt]
INTO result
[SEPARATED BY sep]
[RESPECTING BLANKS].
CDNT类型的前导空格会保留,尾部空格都会被去掉,但对String类型所有空格都会保留;对于c, d, n, t类型的字符串有一个RESPECTING BLANKS选项可使用,表示尾部空格也会保留。注:使用 `` 对String类型进行赋值时才会保留尾部空格 字符串连接可以使用 && 来操作,具体请参考这里
strlen(arg)、Xstrlen(arg)String类型的尾部空格会计入字符个数中,但C类型的变量尾部空格不会计算入
substring( val = TEXT [off = off] [len = len] )
count( val = TEXT {sub = substring}|{regex = regex} )匹配指定字符串substring或正则式regex出现的子串次数,返回的类型为i整型类型
contains( val = TEXT REGEX = REGEX)是否包含。返回布尔值,注:只能用在if、While等条件表达式中
matches( val = TEXT REGEX = REGEX)regex表达式要与text完全匹配,这与contains是不一样的。返回布尔值,也只能用在if、While等条件表达式中
match( val = TEXT REGEX = REGEX occ = occ)返回的为匹配到的字符串。注:每次只匹配一个。occ:表示需匹配到第几次出现的子串。如果为正,则从头往后开始计算,如果为负,则从尾部向前计算
find( val = TEXT {sub = substring}|{regex = regex}[occ = occ] )查找substring或者匹配regex的子串的位置。如果未找到,则返回 -1,返回的为offset,所以从0开始
FIND ALL OCCURRENCES OF REGEX regex IN dobj
[MATCH COUNT mcnt] 成功匹配的次数
{ {[MATCH OFFSET moff][MATCH LENGTH mlen]}最后一次整体匹配到的串(整体串,最外层分组,而不是指正则式最内最后一个分组)起始位置与长度
| [RESULTS result_tab|result_wa] } result_tab接收所有匹配结果,result_wa只能接收最后一次匹配结果
[SUBMATCHES s1 s2 ...].通常与前面的MATCH OFFSET/ LENGTH一起使用。只会接收使用括号进行分组的子组。如果变量s1 s2 ...比分组的数量多,则多余的变量被initial;如果变量s1 s2 ...比分组的数量少,则多余的分组将被忽略;且只存储第一次或最后一次匹配到的结果
replace( val = TEXT REGEX = REGEX WITH = NEW)使用new替换指定的子符串,返回String类型
REPLACE ALL OCCURRENCES OF REGEX regex IN dobj WITH new
1.7.1. count、match结合
DATA: text TYPE string VALUE `Cathy's cat with the hat sat on Matt's mat.`,
regx TYPE string VALUE `\<.at\>`."\< 单词开头,\> 单词结尾
DATA: counts TYPE i,
index TYPE i,
substr TYPE string.
WRITE / text.
NEW-LINE.
counts = count( val = text regex = regx )."返回匹配次数
DO counts TIMES.
index = find( val = text regex = regx occ = sy-index )."返回匹配到的的起始位置索引
substr = match( val = text regex = regx occ = sy-index )."返回匹配到的串
index = index + 1.
WRITE AT index substr.
ENDDO.
![]()
1.7.2.FIND …SUBMATCHES
DATA: moff TYPE i,
mlen TYPE i,
s1 TYPE string,
s2 TYPE string,
s3 TYPE string,
s4 TYPE string.
FIND ALL OCCURRENCES OF REGEX `((\w+)\W+\2\W+(\w+)\W+\3)`"\2 \3 表示反向引用前面匹配到的第二与第三个子串
IN `Hey hey, my my, Rock and roll can never die Hey hey, my my`"会匹配二次,但只会返回第二次匹配到的结果,第一次匹配到的子串不会存储到s1、s2、s3中去
IGNORING CASE
MATCH OFFSET moff
MATCH LENGTH mlen
SUBMATCHES s1 s2 s3 s4."根据从外到内,从左到右的括号顺序依次存储到s1 s2…中,注:只取出使用括号括起来的子串,如想取整体子串则也要括起来,这与Java不同
WRITE: / s1, / s2,/ s3 ,/ s4,/ moff ,/ mlen."s4会被忽略

1.7.3. FIND …RESULTS itab
DATA: result TYPE STANDARD TABLE OF string WITH HEADER LINE .
"与Java不同,只要是括号括起来的都称为子匹配(即使用整体也用括号括起来了),
"不管括号嵌套多少层,统称为子匹配,且匹配到的所有子串都会存储到,
"MATCH_RESULT-SUBMATCHES中,即使最外层的括号匹配到的子串也会存储到SUBMATCHES
"内表中。括号解析的顺序为:从外到内,从左到右的优先级顺序来解析匹配结构。
"Java中的group(0)存储的是整体匹配串,即使整体未(或使用)使用括号括起来
PERFORM get_match TABLES result
USING '2011092131221032' '(((\d{2})(\d{2}))(\d{2})(\d{2}))'.
LOOP AT result .
WRITE: / result.
ENDLOOP.
FORM get_match TABLES p_result"返回所有分组匹配(括号括起来的表达式)
USING p_str
p_reg.
DATA: result_tab TYPE match_result_tab WITH HEADER LINE.
DATA: subresult_tab TYPE submatch_result_tab WITH HEADER LINE.
"注意:带表头时 result_tab 后面一定要带上中括号,否则激活时出现奇怪的问题
FIND ALL OCCURRENCES OF REGEX p_reg IN p_str RESULTS result_tab[].
"result_tab中存储了匹配到的子串本身(与Regex整体匹配的串,存储在
"result_tab-offset、result_tab-length中)以及所子分组(括号部分,存储在
"result_tab-submatches中)
LOOP AT result_tab .
"如需取整体匹配到的子串(与Regex整体匹配的串),则使用括号将整体Regex括起来
"来即可,括起来后也会自动存储到result_tab-submatches,而不需要在这里像这样读取
* p_result = p_str+result_tab-offset(result_tab-length).
* APPEND p_result.
subresult_tab[] = result_tab-submatches.
LOOP AT subresult_tab.
p_result = p_str+subresult_tab-offset(subresult_tab-length).
APPEND p_result.
ENDLOOP.
ENDLOOP.
ENDFORM.


1.7.4.正则式类
regex = Regular expression [ˈreɡjulə]
cl_abap_regex:与Java中的 java.util.regex.Pattern的类对应
cl_abap_matcher:与Java中的 java.util.regex.Matcher的类对应
1.7.4.1.matches、match
是否完全匹配(正则式中不必使用 ^ 与 $);matches为静态方法,而match为实例方法,作用都是一样
DATA: matcher TYPE REF TO cl_abap_matcher,
match TYPE match_result,
match_line TYPE submatch_result.
"^$可以省略,因为matches方法本身就是完全匹配整个Regex
IF cl_abap_matcher=>matches( pattern = '^(db(ai).*)$' text = 'dbaiabd' ) = 'X'.
matcher = cl_abap_matcher=>get_object( )."获取最后一次匹配到的 Matcher 实例
match = matcher->get_match( ). "获取最近一次匹配的结果(注:是整体匹配的结果)
WRITE / matcher->text+match-offset(match-length).
LOOP AT match-submatches INTO match_line. "提取子分组(括号括起来的部分)
WRITE: /20 match_line-offset, match_line-length,matcher->text+match_line-offset(match_line-length).
ENDLOOP.
ENDIF.
![]()
DATA: matcher TYPE REF TO cl_abap_matcher,
match TYPE match_result,
match_line TYPE submatch_result.
"^$可以省略,因为matche方法本身就是完全匹配整个Regex
matcher = cl_abap_matcher=>create( pattern = '^(db(ai).*)$' text = 'dbaiabd' ).
IF matcher->match( ) = 'X'.
match = matcher->get_match( ). "获取最近一次匹配的结果
WRITE / matcher->text+match-offset(match-length).
LOOP AT match-submatches INTO match_line. "提取子分组(括号括起来的部分)
WRITE: /20 match_line-offset, match_line-length,matcher->text+match_line-offset(match_line-length).
ENDLOOP.
ENDIF.
![]()
1.7.4.2.contains
是否包含(也可在正则式中使用 ^ 与 $ 用于完全匹配检查,或者使用 ^ 检查是否匹配开头,或者使用 $ 匹配结尾)
DATA: matcher TYPE REF TO cl_abap_matcher,
match TYPE match_result,
match_line TYPE submatch_result.
IF cl_abap_matcher=>contains( pattern = '(db(ai).{2}b)' text = 'dbaiabddbaiabb' ) = 'X'.
matcher = cl_abap_matcher=>get_object( ). "获取最后一次匹配到的 Matcher 实例
match = matcher->get_match( ). "获取最近一次匹配的结果
WRITE / matcher->text+match-offset(match-length).
LOOP AT match-submatches INTO match_line. "提取子分组(括号括起来的部分)
WRITE: /20 match_line-offset, match_line-length,matcher->text+match_line-offset(match_line-length).
ENDLOOP.
ENDIF.
![]()
1.7.4.3.find_all
一次性找出所有匹配的子串,包括子分组(括号括起的部分)
DATA: matcher TYPE REF TO cl_abap_matcher,
match_line TYPE submatch_result,
itab TYPE match_result_tab WITH HEADER LINE.
matcher = cl_abap_matcher=>create( pattern = '<[^<>]*(ml)>' text = 'hello' )."创建 matcher 实例
"注:子分组存储在itab-submatches字段里
itab[] = matcher->find_all( ).
LOOP AT itab .
WRITE: / matcher->text, itab-offset, itab-length,matcher->text+itab-offset(itab-length).
LOOP AT itab-submatches INTO match_line. "提取子分组(括号括起来的部分)
WRITE: /20 match_line-offset, match_line-length,matcher->text+match_line-offset(match_line-length).
ENDLOOP.
ENDLOOP.

1.7.4.4.find_next
逐个找出匹配的子串,包括子分组(括号括起的部分)
DATA: matcher TYPE REF TO cl_abap_matcher,
match TYPE match_result, match_line TYPE submatch_result,
itab TYPE match_result_tab WITH HEADER LINE.
matcher = cl_abap_matcher=>create( pattern = '<[^<>]*(ml)>' text = 'hello' ).
WHILE matcher->find_next( ) = 'X'.
match = matcher->get_match( )."获取最近一次匹配的结果
WRITE: / matcher->text, match-offset, match-length,matcher->text+match-offset(match-length).
LOOP AT match-submatches INTO match_line. "提取子分组(括号括起来的部分)
WRITE: /20 match_line-offset, match_line-length,matcher->text+match_line-offset(match_line-length).
ENDLOOP.
ENDWHILE.

1.7.4.5.get_length、get_offset、get_submatch
DATA: matcher TYPE REF TO cl_abap_matcher,
length TYPE i,offset TYPE i,
submatch TYPE string.
matcher = cl_abap_matcher=>create( pattern = '(<[^<>]*(ml)>)' text = 'hello' ).
WHILE matcher->find_next( ) = 'X'. "循环2次
"为0时,表示取整个Regex匹配到的子串,这与Java一样,但如果整个Regex使用括号括起来后,
"则分组索引为1,这又与Java不一样(Java不管是否使用括号将整个Regex括起来,分组索引号都为0)
"上面Regex中共有两个子分组,再加上整个Regex为隐含分组,所以一共为3组
DO 3 TIMES.
"在当前匹配到的串(整个Regex相匹配的串)中返回指定子分组的匹配到的字符串长度
length = matcher->get_length( sy-index - 1 ).
"在当前匹配到的串(整个Regex相匹配的串)中返回指定子分组的匹配到的字符串起始位置
offset = matcher->get_offset( sy-index - 1 ).
"在当前匹配到的串(整个Regex相匹配的串)中返回指定子分组的匹配到的字符串
submatch = matcher->get_submatch( sy-index - 1 ).
WRITE:/ length , offset,matcher->text+offset(length),submatch.
ENDDO.
SKIP.
ENDWHILE.

1.7.4.6.replace_all
DATA: matcher TYPE REF TO cl_abap_matcher,
count TYPE i,
repstr TYPE string.
matcher = cl_abap_matcher=>create( pattern = '<[^<>]*>' text = 'hello' ).
count = matcher->replace_all( ``)."返回替换的次数
repstr = matcher->text. "获取被替换后的新串
WRITE: / count , repstr.
![]()
1.8.CLEAR、REFRESH、FREE
内表:如果使用有表头行的内表,CLEAR 仅清除表格工作区域。要重置整个内表而不清除表格工作区域,使用REFRESH语句或 CLEAR 语句CLEAR [].;REFRESH加不加中括号都是只清内表,另外REFRESH是专为清内表的,不能清基本类型变量,但CLEAR可以
以上都不会释放掉内表所占用的空间,如果想初始化内表的同时还要释放所占用的空间,请使用:FREE .
1.9.ABAP程序中的局部与全局变量
报表程序中选择屏幕事件块(AT SELECTION-SCREEN)与逻辑数据库事件块、以及methods(类中的方法)、subroutines(FORM子过程)、function modules(Function函数)中声明的变量为局部的,即在这些块里声明的变量不能在其他块里使用,但这些局部变量可以覆盖同名的全局变量;除这些处理块外,其他块里声明的变量都属于全局的(如报表事件块、列表事件块、对话Module),效果与在程序最开头定义的变量效果是一样的,所以可以在其他处理块直接使用(但要注意的是,需遵守先定义后使用的原则,这种先后关系是从语句书写顺序来说的,与事件块的本身运行顺序没有关系);另外,局部变量声明时,不管在处理块的任何地方,其效果都是相当于处理块里的全局变量,而不像其他语言如Java那样:局部变量的作用域可以存在于任何花括号{}之间(这就意味着局部变量在处理过程范围内是全局的),如下面的i,在ABAP语言中还是会累加输出,而不会永远是1(在Java语言中会是1):
FORM aa.
DO 10 TIMES.
DATA: i TYPE i VALUE 0.
i = i + 1.
WRITE: / i.
ENDDO.
ENDFORM.
1.10.Form、Function
Form、Function中的TABLES参数,TYPE与LIKE后面只能接标准内表类型或标准内表对象,如果要使用排序内表或者哈希内表,则只能使用USING(Form)与CHANGING方式来代替。当把一个带表头的实参通过TABLES参数传递时,表头也会传递过去,如果实参不带表头或者只传递了表体(使用了[]时),系统会自动为内表参数变量创建一个局部空的表头
不管是以TABLES还是以USING(Form)非值、CHANGE非值方式传递时,都是以引用方式(即别名,不是指地址,注意与Java中的传引用区别:Java实为传值,但传递的值为地址的值,而ABAP中传递的是否为地址,则要看实参是否是通过Type ref to定义的)传递;但如果USING值传递,则对形参数的修改不会改变实参,因为此时不是引用传递;但如果CHANGE值传递,对形参数的修改还是会改变实参,只是修改的时机在Form执行或Function执行完后,才去修改
Form中通过引用传递时,USING与CHANGING完全一样;但CHANGING为值传递方式时,需要在Form执行完后,才去真正修改实参变量的内容,所以CHANGING传值与传引用其结果都是一样:结果都修改了实参内容,只是修改的时机不太一样而已
1.10.1.FORM
FORM subr [TABLES t1 [{TYPE itab_type}|{LIKE itab}|{STRUCTURE struc}]
t2 […]]
[USING { VALUE(p1)|p1 } [ { TYPE generic_type }
| { LIKE |generic_para }
| { TYPE {[LINE OF] complete_type}|{REF TO type} }
| { LIKE {[LINE OF] dobj} | {REF TO dobj} }
| STRUCTURE struc]
{ VALUE(p2)|p2 } […]]
[CHANGING{ VALUE(p1)|p1 } [ { TYPE generic_type }
| { LIKE |generic_para }
| { TYPE {[LINE OF] complete_type} | {REF TO type} }
| { LIKE {[LINE OF] dobj} | {REF TO dobj} }
| STRUCTURE struc]
{ VALUE(p2)|p2 } […]]
[RAISING {exc1|RESUMABLE(exc1)} {exc2|RESUMABLE(exc2)} ...].
generic_type:为通用类型
complete_type:为完全限制类型
:为字段符号变量类型,如下面的 fs 形式参数
generic_para:为另一个形式参数类型,如下面的 b 形式参数
DATA: d(10) VALUE'11'.
FIELD-SYMBOLS: LIKE d.
ASSIGN d TO .
PERFORM aa USING d d.
FORM aa USING fs like a like d b like a.
WRITE:fs,/ a , / b.
ENDFORM.
如果没有给形式参数指定类,则为ANY类型
如果TABLES与USING、CHANGING一起使用时,则一定要按照TABLES、USING、CHANGING顺序声明
值传递中的VALUE关键字只是在FORM定义时出现,在调用时PERFORM语句中无需出现,也就是说,调用时值传递和引用传递不存在语法格式差别
DATA : i TYPE i VALUE 100.
WRITE: / 'frm_ref===='.
PERFORM frm_ref USING i .
WRITE: / i."200
WRITE: / 'frm_val===='.
i = 100.
PERFORM frm_val USING i .
WRITE: / i."100
WRITE: / 'frm_ref2===='.
"不能将下面的变量定义到frm_ref2过程中,如果这样,下面的dref指针在调用frm_ref2 后,指向的是Form中局部变量内存,为不安全发布,运行会抛异常,因为From结束后,它所拥有的所有变量内存空间会释放掉
DATA: i_frm_ref2 TYPE i VALUE 400.
i = 100.
DATA: dref TYPE REF TO i .
get REFERENCE OF i INTO dref.
PERFORM frm_ref2 USING dref ."传递的内容为地址,属于别名引用传递
WRITE: / i."4000
field-SYMBOLS : TYPE i .
ASSIGN dref->* to ."由于frm_ref2过程中已修改了dref的指向,现指向了i_frm_ref2 变量的内存空间
WRITE: / ."400
WRITE: / 'frm_val2===='.
i = 100.
DATA: dref2 TYPE REF TO i .
get REFERENCE OF i INTO dref2.
PERFORM frm_val2 USING dref2 .
WRITE: / i."4000
ASSIGN dref2->* to .
WRITE: / ."4000
FORM frm_ref USING p_i TYPE i ."C++中的引用参数传递:p_i为实参i的别名
WRITE: / p_i."100
p_i = 200."p_i为参数i的别名,所以可以直接修改实参
ENDFORM.
FORM frm_val USING value(p_i)."传值:p_i为实参i的拷贝
WRITE: / p_i."100
p_i = 300."由于是传值,所以不会修改主调程序中的实参的值
ENDFORM.
FORM frm_ref2 USING p_i TYPE REF TO i ."p_i为实参dref的别名,类似C++中的引用参数传递(传递的内容为地址,并且属于别名引用传递)
field-SYMBOLS : TYPE i .
"现在就是实参所指向的内存内容的别名,代表实参所指向的实际内容
ASSIGN p_i->* to .
WRITE: / ."100
= 4000."直接修改实参所指向的实际内存
DATA: dref TYPE REF TO i .
get REFERENCE OF i_frm_ref2 INTO dref.
"由于USING为C++的引用参数,所以这里修改的直接是实参所存储的地址内容,这里的p_i为传进来的dref的别名,是同一个变量,所以实参的指向也发生了改变(这与Java中传递引用是不一样的,Java中传递引用时为地址的拷贝,即Java中永远也只有传值,但C/C++/ABAP中可以传递真正引用——别名)
p_i = dref."此处会修改实参的指向
ENDFORM.
FORM frm_val2 USING VALUE(p_i) TYPE REF TO i ."p_i为实参dref2的拷贝,类似Java中的引用传递(虽然传递的内容为地址,但传递的方式属于地址拷贝——值传递)
field-SYMBOLS : TYPE i .
"现在就是实参所指向的内存内容的别名,代表实参所指向的实际内容
ASSIGN p_i->* to .
WRITE: / ."100
= 4000."但这里还是可以直接修改实参所指向的实际内容
DATA: dref TYPE REF TO i .
get REFERENCE OF i_frm_ref2 INTO dref.
"这里与过程 frm_ref2 不一样,该过程 frm_val2 参数的传递方式与java中的引用传递是原理是一样的:传递的是地址拷贝,所以下面不会修改主调程序中实参dref2的指向,它所改变的只是拷贝过来的Form中局部形式参数的指向
p_i = dref.
ENDFORM.
1.10.2.FUNCTION

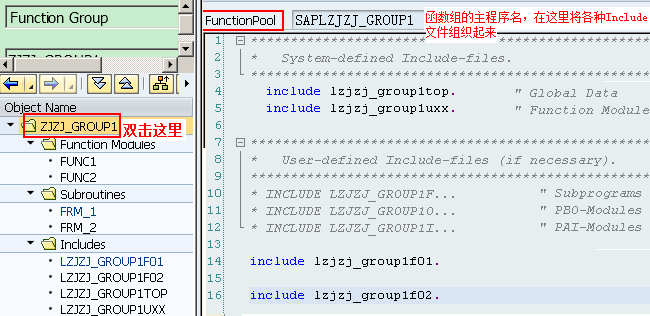
1.10.2.1. Function Group结构
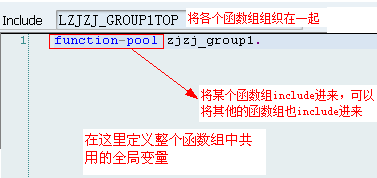
当使用Function Builder创建函数组时,系统会自动创建main program与相应的include程序:
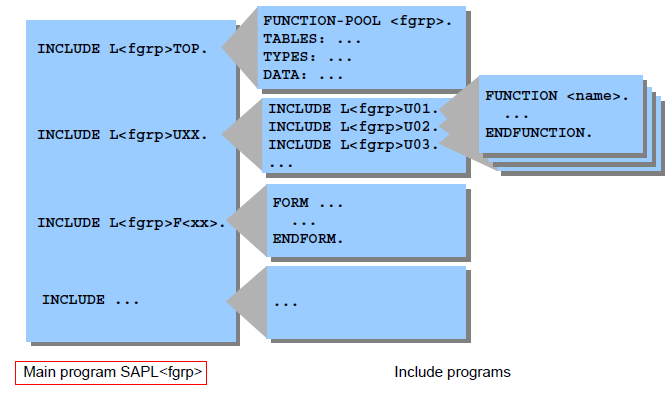
l为Function Group的名称
lSAPL为主程序名,它将Function Group里的所有Include文件包括进来,除了INCLUDE语句之外,没有其他语句了
lLTOP,里面有FUNCTION-POOL语句,以及所有Function Module都可以使用的全局数据定义
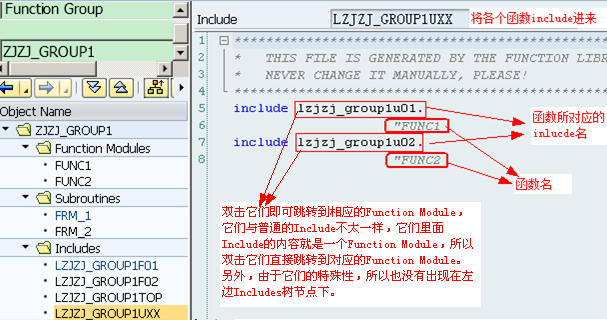
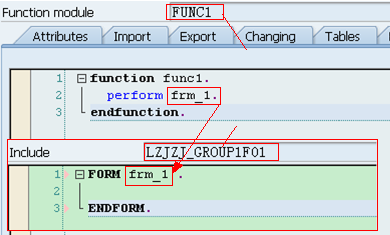
lLUXX,也只有INCLUDE语句,它所包括的Include文件为相应具体Function Module所对应Include文件名:LU01、LU02、...这些Include文件实际上包含了所对应的Function Module代码(即双击它们进去就是对应的Function,而显示的不是真正Include文件所对应的代码)
lLU01和LU02中的01、02编号对应LUXX中的“XX”,代表其创建先后的序号,例如LU01和LU02是头两个被创建的函数,在函数组中创建出的函数代码就放在相应的LUXX(这里的XX代表某个数字,而不是字面上的XX)Include头文件中
lLFXX,用来存一些Form子过程,并且可以被所有的Function Modules所使用(不是针对某个Function Module的,但一般在设计时会针对每个Function Module设计这样单独的Include文件,这是一个好习惯),并且在使用时不需要在Function Module中使用INCLUDE语句包含它们(因为这些文件在主程序SAPL里就已经被Include进来了)。另外,LFXX中的F是指Form的意思,这是一种名称约束而已,在创建时我们可以随便指定,一般还有IXX(表示些类Include文件包括的是一些PAI事件中调用的Module,有时干脆直接使用LPAI或者LPAIXX),OXX(表示些类Include文件包括的是一些PBO事件中调用的Module,有时干脆直接使用LPBO或者LPBOXX)。注:如果Form只被某一函数单独使用,实质上还可直接将这些Form定义在Function Module里的ENDFUNCTION语句后面
当你调用一个function module时,系统加将整个function group(包括Function Module、Include文件等)加载到主调程序所在的internal session中,然后该Function Module得到执行,该Function Group一直保留在内存中,直到internal session结束。Function Group中的所定义的Include文件中的变量是全局,被所有Function Module共享,所以Function Group好比Java中的类,而Function Module则好比类中的方法,所以Function Group中的Include文件中定义的东西是全局型的,能被所有Function Module所共享使用
1.10.2.2.Function参数传值、传址
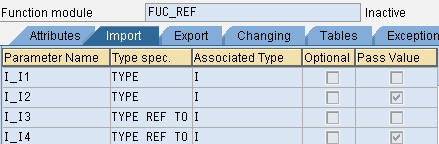
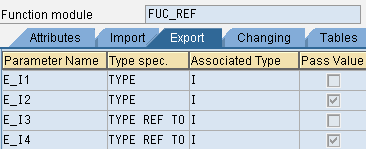
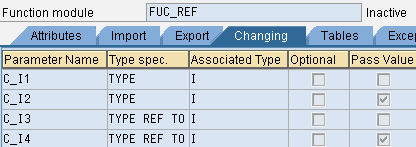
function fuc_ref .
*"-------------------------------------------------------------------
*"*"Local Interface:
*" IMPORTING
*" REFERENCE(I_I1) TYPE IREFERENCE(别名)为参数的默认传递类型
*" VALUE(I_I2) TYPE I 定义时勾选了Pass Value选项才会是 VALUE类型
*" REFERENCE(I_I3) TYPE REF TO I
*" VALUE(I_I4) TYPE REF TO I
*" EXPORTING
*" REFERENCE(E_I1) TYPE I
*" VALUE(E_I2) TYPE I
*" REFERENCE(E_I3) TYPE REF TO I
*" VALUE(E_I4) TYPE REF TO I
*" TABLES
*" T_1 TYPE ZJZJ_ITAB
*" CHANGING
*" REFERENCE(C_I1) TYPE I
*" VALUE(C_I2) TYPE I
*" REFERENCE(C_I3) TYPE REF TO I
*" VALUE(C_I4) TYPE REF TO I
*"-------------------------------------------------------------------
write: / i_i1."1
"由于i_i1为输入类型参数,且又是引用类型,实参不能被修改。这里i_i1是以C++中的引用(别名)参数方式传递参数,所以如果修改了i_i1就会修改实际参数,所以函数中不能修改REFERENCE 的 IMPORTING类型的参数,如果去掉下面注释则编译出错
"i_i1 = 10.
write: / i_i2."2
"虽然i_i2是输入类型的参数,但不是引用类型,所以可以修改,编译能通过但不会修改外面实参的值,只是修改了该函数局部变量的值
i_i2 = 20.
field-symbols: type i .
assign i_i3->* to .
"由于i_i3存储的是地址,所以先要解引用再能使用
write: / .
"同上面,REFERENCE的IMPORTING类型的参数不能被修改:这里即不能修改实参的指向"GET REFERENCE OF 30 INTO i_i3."虽然不可以修改实参的指向,但可以修改实参所指向的实际内容
= 30.
assign i_i4->* to .
"i_i4存储也的是地址,所以先要解引用再能使用
write: / .
"虽然i_i4是输入类型的参数,但不是引用类型,所以可以修改,只会修改函数中的局部参数i_i4的指向,但并不会修改实参的指向
get reference of 40 into i_i4.
"虽然不能修改实参的指向,但可以直接修改实参的所指向的实际内容
= 400.
WRITE: / c_i1."111
"c_i1为实参的别名,修改形参就等于修改实参内容
c_i1 = 1110.
WRITE: / c_i2."222
"c_i2为实参的副本,所以不会影响实参的内容,但是,由于是CHANGING类型的参数,且为值传递,在函数正常执行完后,还是会将该副本再次拷贝给实参,所以最终实参还是会被修改
c_i2 = 2220.
ENDFUNCTION.
调用程序:
DATA: i_i1 TYPE i VALUE 1,
i_i2 TYPE i VALUE 2,
i_i3 TYPE REF TO i ,
i_i4 TYPE REF TO i ,
c_i1 TYPE i VALUE 111,
c_i2 TYPE i VALUE 222,
c_i3 TYPE REF TO i ,
c_i4 TYPE REF TO i ,
t_1 TYPE zjzj_itab WITH HEADER LINE.
DATA: i_i3_ TYPE i VALUE 3.
GET REFERENCE OF i_i3_ INTO i_i3.
DATA: i_i4_ TYPE i VALUE 4.
GET REFERENCE OF i_i4_ INTO i_i4.
DATA: c_i3_ TYPE i VALUE 333.
GET REFERENCE OF c_i3_ INTO c_i3.
DATA: c_i4_ TYPE i VALUE 444.
GET REFERENCE OF c_i4_ INTO c_i4.
CALL FUNCTION 'FUC_REF'
EXPORTING
i_i1 = i_i1
i_i2 = i_i2
i_i3 = i_i3
i_i4 = i_i4
TABLES
t_1 = t_1
CHANGING
c_i1 = c_i1
c_i2 = c_i2
c_i3 = c_i3
c_i4 = c_i4.
WRITE: / i_i2."2
WRITE: / i_i3_."30
WRITE: / i_i4_."400
WRITE: / c_i1."1110
WRITE: / c_i2."2220
1.11. 字段符号FIELD-SYMBOLS
字段符号可以看作仅是已经被解引用的指针(类似于C语言中带有解引用操作符 * 的指针),但更像是C++中的引用类型(int i ;&ii= i;),即某个变量的别名,它与真正的指针还是有很大的区别的,在ABAP中引用变量(通过TYPE REF TO定义的变量)才好比C语言中的指针
ASSIGN ... TO :将某个内存区域分配给字段符号,这样字段符号就代表了该内存区域,即该内存区域别名
1.11.1.ASSIGN隐式强转
TYPES: BEGIN OF t_date,
year(4) TYPE n,
month(2) TYPE n,
day(2) TYPE n,
END OF t_date.
FIELD-SYMBOLS TYPE t_date."将定义成了具体限定类型
ASSIGN sy-datum TO CASTING. "后面没有指定具体类型,所以使用定义时的类型进行隐式转换
1.11.2.ASSIGN显示强转
DATA txt(8) TYPE c VALUE '19980606'.
FIELD-SYMBOLS .
ASSIGN txt TO CASTING TYPE d."由于定义时未指定具体的类型,所以这里需要显示强转
1.11.3.ASSIGN 动态分配
请参考动态语句à ASSIGN 动态分配
1.11.4.UNASSIGN、CLEAR
UNASSIGN:该语句是初始化字段符号,执行后字段符号将不再引用内存区域, is assigned返回假
CLEAR:与UNASSIGN不同的是,只有一个作用就是初始化它所指向的内存区域,而不是解除分配
1.12.数据引用、对象引用
TYPE REF TO data 数据引用data references
TYPE REF TO object 对象引用object references
除了object,所有的通用类型都能直接用TYPE后面(如TYPE data,但没有TYPE object,object不能直接跟在TYPE后面,只能跟在TYPE REF TO后面)
TYPE REF TO 后面可接的通用类型只能是data(数据引用)或者是object(对象引用)通用类型,其他通用类型不行
1.12.1.数据引用Data References
DATA: dref TYPE REF TO i ."dref即为数据引用,即数据指针,指向某个变量或常量,存储变量地址
CREATE DATA dref.
dref->* = 2147483647."可直接解引用使用,不需要先通过分配给字段符号后再使用
DATA: BEGIN OF strct,
c,
END OF strct.
DATA: dref LIKE REF TO strct .
CREATE DATA dref .
dref->*-c = 'A'.
TYPES: tpy TYPE c.
DATA: c1 TYPE REF TO tpy.
DATA: c2 LIKE REF TO c1."二级指针
GET REFERENCE OF 'a' INTO c1.
GET REFERENCE OF c1 INTO c2.
WRITE: c2->*->*."a
1.12.2.对象引用Object references
CLASS cl DEFINITION.
PUBLIC SECTION.
DATA: i VALUE 1.
ENDCLASS.
CLASS cl IMPLEMENTATION.
ENDCLASS.
DATA: obj TYPE REF TO cl.
CREATE OBJECT obj. "创建对象
DATA: oref LIKE REF TO obj. "oref即为对象引用,即对象指针,指向某个对象,存储对象地址
GET REFERENCE OF obj INTO oref. "获取对象地址
WRITE: oref->*->i."1
1.12.3.GET REFERENCE OF获取变量/对象/常量地址
DATA: e_i3 TYPE REF TO i .
GET REFERENCE OF 33 INTO e_i3.
WRITE: e_i3->*."33
"但不能修改常量的值
"e_i3->* = 44.
DATA: i TYPE i VALUE 33,
dref LIKE REF TO i."存储普通变量的地址
GET REFERENCE OF i INTO dref.
dref->* = 44.
WRITE: i. "44
1.13.动态语句
1.13.1.内表动态访问
SORT itab BY (comp1)...(compn)
READ TABLE itab WITH KEY(k1)=v1...(kn)=vn
READ TABLE itab...INTOwaCOMPARING(comp1)...(compn) TRANSPORTING(comp1)...
MODIFY [TABLE] itab TRANSPORTING(comp1)...(compn)
DELETE TABLEitabWITH TABLE KEY(comp1)...(compn)
DELETE ADJACENT DUPLICATES FROM itab COMPARING(comp1)...(compn)
AT NEW/END OF (comp)
1.13.2.动态类型
CREATE DATA ... TYPE (type)...
DATA: a TYPE REF TO i.
CREATE DATA a TYPE ('I').
a->* = 1.
CREATE OBJECT ... TYPE (type)...请参考类对象反射章节
1.13.3.动态SQL
MODIFY/UPDATE(dbtab)...
1.13.4.动态调用类的方法
CALL METHOD (meth_name)
| cref->(meth_name)
| iref->(meth_name)
| (class_name)=>(meth_name)
| class=>(meth_name)
| (class_name)=>meth
实例请参考类对象反射章节
1.13.5.ASSIGN 动态分配
FIELD-SYMBOLS:.
DATA:str(20) TYPE c VALUE 'Output String',
name(20) TYPE c VALUE 'STR'.
"静态分配:编译时就知道要分配的对象名
ASSIGN name TO ."结果是与name变量等同
"通过变量名动态访问变量
ASSIGN (name) TO ."结果是是的值为str变量值
DATA: BEGIN OF line,
col1 TYPE i VALUE '11',
col2 TYPE i VALUE '22',
col3 TYPE i VALUE '33',
END OF line.
DATA comp(5) VALUE 'COL3'.
FIELD-SYMBOLS: , , .
ASSIGN line TO .
ASSIGN comp TO .
"还可以直接使用以下的语法访问其他程序中的变量
ASSIGN ('(ZJDEMO)SBOOK-FLDATE') TO .
"通过索引动态的访问结构成员
ASSIGN COMPONENT sy-index OF STRUCTURE TO .
"通过字段名动态的访问结构成员
ASSIGN COMPONENT OF STRUCTURE TO .
"如果定义的内表没有组件名时,可以使用索引为0的组件来访问这个无名字段(注:不是1)
ASSIGN COMPONENT 0 OF STRUCTURE itab TO .
1.13.5.1.动态访问类的属性成员
ASSIGN oref->('attr') TO .
ASSIGN oref->('static_attr') TO .
ASSIGN ('C1')=>('static_attr') TO .
ASSIGN c1=>('static_attr') TO .
ASSIGN ('C1')=>static_attr TO .
实例请参考类对象反射章节
1.14.反射
CL_ABAP_TYPEDESCR
|--CL_ABAP_DATADESCR
| |--CL_ABAP_ELEMDESCR
| |--CL_ABAP_REFDESCR
| |--CL_ABAP_COMPLEXDESCR
| |--CL_ABAP_STRUCTDESCR
| |--CL_ABAP_TABLEDESCR
|--CL_ABAP_OBJECTDESCR
|--CL_ABAP_CLASSDESCR
|--CL_ABAP_INTFDESCR
DATA: structtype TYPE REF TO cl_abap_structdescr.
structtype ?= cl_abap_typedescr=>describe_by_name( 'spfli' ).
*COMPDESC-TYPE ?= CL_ABAP_DATADESCR=>DESCRIBE_BY_NAME( 'EKPO-MATNR' ).
DATA: datatype TYPE REF TO cl_abap_datadescr,
field(5) TYPE c.
datatype ?= cl_abap_typedescr=>describe_by_data( field ).
DATA: elemtype TYPE REF TO cl_abap_elemdescr.
elemtype = cl_abap_elemdescr=>get_i( ).
elemtype = cl_abap_elemdescr=>get_c( 20 ).
DATA: oref1 TYPE REF TO object.
DATA: descr_ref1 TYPE REF TO cl_abap_typedescr.
CREATE OBJECT oref1 TYPE ('C1'). "C1为类名
descr_ref1 = cl_abap_typedescr=>describe_by_object_ref( oref1 ).
还有一种:describe_by_data_ref
1.14.1.TYPE HANDLE
handle只能是CL_ABAP_DATADESCR或其子类的引用变量,注:只能用于Data类型,不能用于Object类型,即不能用于CL_ABAP_ OBJECTDESCR,所以没有:
CREATE OBJECT dref TYPE HANDLE objectDescr.
DATA: dref TYPE REF TO data,
c10type TYPE REF TO cl_abap_elemdescr.
c10type = cl_abap_elemdescr=>get_c( 10 ).
CREATE DATA dref TYPE HANDLE c10type.
DATA: x20type TYPE REF TO cl_abap_elemdescr.
x20type = cl_abap_elemdescr=>get_x( 20 ).
FIELD-SYMBOLS: TYPE any.
ASSIGN dref->* TO CASTING TYPE HANDLE x20type.
1.14.2.动态创建数据Data或对象Object
TYPES: ty_i TYPE i.
DATA: dref TYPE REF TO ty_i .
CREATE DATA dref TYPE ('I')."根据基本类型名动态创建数据
dref->* = 1.
WRITE: / dref->*." 1
CREATE OBJECT oref TYPE ('C1')."根据类名动态创建实例对象
1.14.3.动态创建基本类型变量、结构、内表
DATA: dref_str TYPE REF TO data,
dref_tab TYPE REF TO data,
dref_i TYPE REF TO data,
itab_type TYPE REF TO cl_abap_tabledescr,
struct_type TYPE REF TO cl_abap_structdescr,
elem_type TYPE REF TO cl_abap_elemdescr,
table_type TYPE REF TO cl_abap_tabledescr,
comp_tab TYPE cl_abap_structdescr=>component_table WITH HEADER LINE.
FIELD-SYMBOLS : TYPE ANY TABLE.
**=========动态创建基本类型
elem_type ?= cl_abap_elemdescr=>get_i( ).
CREATE DATA dref_i TYPE HANDLE elem_type ."动态的创建基本类型数据对象
**=========动态创建结构类型
struct_type ?= cl_abap_typedescr=>describe_by_name( 'SFLIGHT' )."结构类型
comp_tab[] = struct_type->get_components( )."组成结构体的各个字段组件
* 向结构中动态的新增一个成员
comp_tab-name = 'L_COUNT'."为结构新增一个成员
comp_tab-type = elem_type."新增成员的类型对象
INSERT comp_tab INTO comp_tab INDEX 1.
* 动态创建结构类型对象
struct_type = cl_abap_structdescr=>create( comp_tab[] ).
CREATE DATA dref_str TYPE HANDLE struct_type."使用结构类型对象来创建结构对象
**=========动态创建内表
* 基于结构类型对象创建内表类型对象
itab_type = cl_abap_tabledescr=>create( struct_type ).
CREATE DATA dref_tab TYPE HANDLE itab_type."使用内表类型对象来创建内表类型
ASSIGN dref_tab->* TO ."将字段符号指向新创建出来的内表对象
"**========给现有的内表动态的加一列
table_type ?= cl_abap_tabledescr=>describe_by_data( itab ).
struct_type ?= table_type->get_table_line_type( ).
comp_tab[] = struct_type->get_components( ).
comp_tab-name = 'FIDESC'.
comp_tab-type = cl_abap_elemdescr=>get_c( 120 ).
INSERT comp_tab INTO comp_tab INDEX 2.
struct_type = cl_abap_structdescr=>create( comp_tab[] ).
itab_type = cl_abap_tabledescr=>create( struct_type ).
CREATE DATA dref_tab TYPE HANDLE itab_type.
1.14.4.类对象反射
CLASS c1 DEFINITION.
PUBLIC SECTION.
DATA: c VALUE 'C'.
METHODS: test.
ENDCLASS.
CLASS c1 IMPLEMENTATION.
METHOD:test.
WRITE:/ 'test'.
ENDMETHOD.
ENDCLASS.
START-OF-SELECTION.
TYPES: ty_c.
DATA: oref TYPE REF TO object .
DATA: oref_classdescr TYPE REF TO cl_abap_classdescr .
CREATE OBJECT oref TYPE ('C1')."根据类名动态创建实例对象
"相当于Java中的Class类对象
oref_classdescr ?= cl_abap_classdescr=>describe_by_object_ref( oref ).
DATA: t_attrdescr_tab TYPE abap_attrdescr_tab WITH HEADER LINE,"类中的属性列表
t_methdescr_tab TYPE abap_methdescr_tab WITH HEADER LINE."类中的方法列表
FIELD-SYMBOLS TYPE any.
t_attrdescr_tab[] = oref_classdescr->attributes.
t_methdescr_tab[] = oref_classdescr->methods.
LOOP AT t_attrdescr_tab."动态访问类中的属性
ASSIGN oref->(t_attrdescr_tab-name) TO .
WRITE: / .
ENDLOOP.
LOOP AT t_methdescr_tab."动态访问类中的方法
CALL METHOD oref->(t_methdescr_tab-name).
ENDLOOP.
![]()
